
TensorFlow で 画像分類モデルを構築してみた・前編
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
こんにちは!よしななです。
今回は、TensorFlow による私の飼い猫とそれ以外の猫の判別モデルを構築し、テストデータを用いてモデルの評価をするところまでをまとめたので備忘録として残します。
構築したモデルの精度改善については「TensorFlow で 画像分類モデルを構築してみた・後編」で扱いたいと思います。
目次
- 開発環境・実行環境について
- 目的
- ディレクトリ構成
- データセットの準備
- 画像データの用意
- Google Colab データアップロード / 解凍
- データの分割
- データの前処理
- 画像データの前処理について
- 今回実施する前処理について
- データセットの最適化
- モデルの構築とトレーニング、学習過程の可視化
- 今回使用するモデルについて
- 1.モデルのレイヤーを定義
- 2.モデルのコンパイル
- モデルトレーニング
- CNN の学習過程を可視化
- モデルの精度評価
- データの用意
- テストデータでのモデルの予測・評価
- 終わりに
開発環境・実行環境について
google colab を使用し、データ前処理~テストデータを用いてモデル評価までを実行します。
実行環境は以下の通りです。
- 実行環境
- Google Colaboratory 上でモデルの構築を実行
- python : 3.9
- 各ライブラリは Google Colab 上でインポートする
- Google Colaboratory 上でモデルの構築を実行
目的
TensorFlow を使用して、私の飼い猫とそれ以外の猫の判別モデルを構築し、テストデータを用いてモデル評価するまでを行います。
飼い猫:

それ以外の猫:


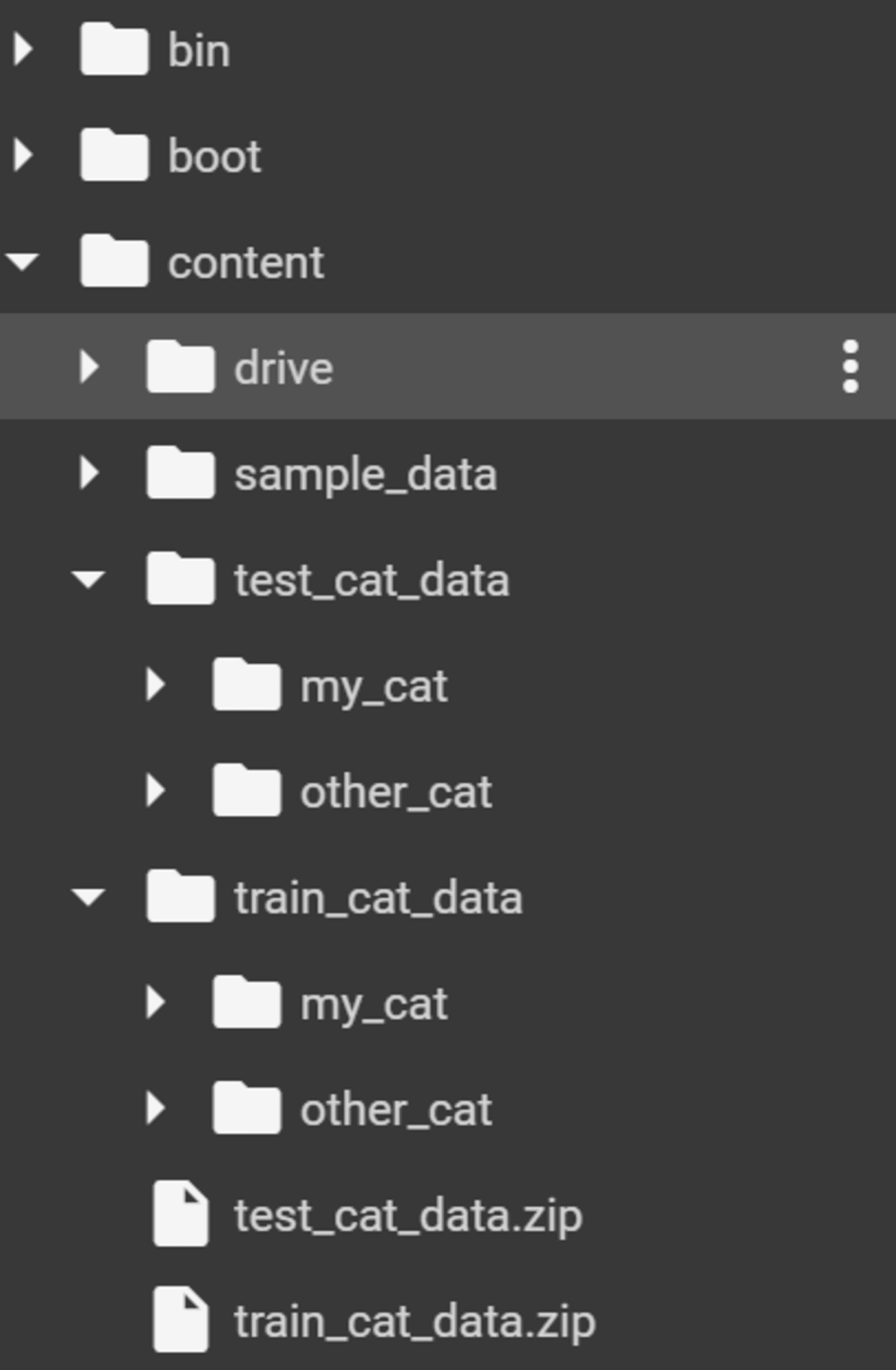
ディレクトリ構成
モデル構築に使用したデータは Google Colab ディレクトリ./content配下に配置しました。
データセットの準備
画像データの用意
正解データとして、自分で撮影した飼い猫の画像200枚を用意しました。
iphone の画像は .heic 形式になっているので、こちらを .jpg に変換し、画像ファイルのリネームを行いました。
一括リネーム方法 :
用意したデータ :
次に、kaggle のデータセットから猫の画像200枚を用意しました。
自分で用意した画像と Kaggle のデータセットを以下の通りフォルダ分け後、.zip 形式にしてデータセットとします。
- 学習用データセット : 400枚
- my_cat : 自分で撮影した飼い猫の写真200枚
- other_cat : Kaggle データセットの猫画像200枚をランダムに取得
- 検証用データセット : 200枚
- my_cat : 自分で撮影した飼い猫の写真100枚
- other_cat : Kaggle データセットの猫画像100枚をランダムに取得
kaggleリンク :
Google Colab データアップロード / 解凍
Google Drive にデータをアップロード / マウント
前項で用意した学習用データと検証用データを .zip 形式にまとめ、Google Drive にアップロードします。
Google Colab を開き、以下の通り Google Drive をマウントします。
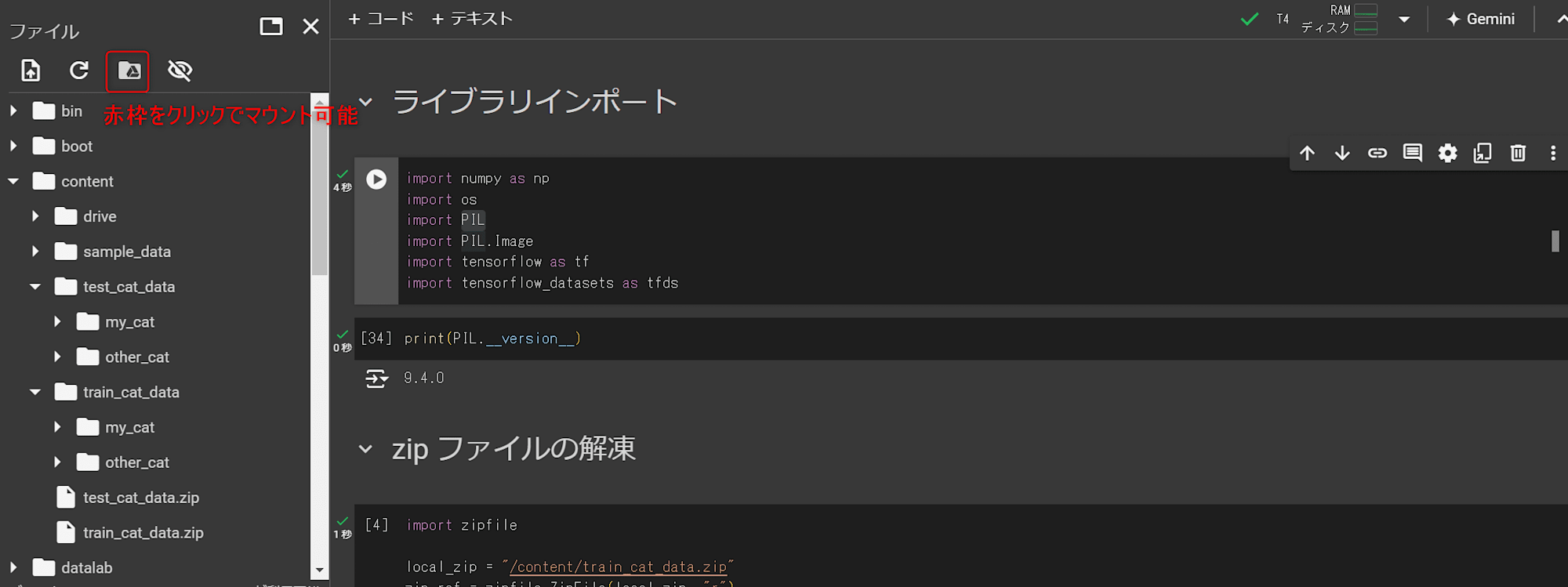
Google Drive に配置した .zip データを /content 配下に移動させます。
こちらで、データを解凍する準備が整ったので .zip データを解凍します。
フォルダの解凍
Notebook を開き、以下のコードを実行しフォルダを解凍しました。
import zipfile
local_zip = "/content/cat_data.zip"
zip_ref = zipfile.ZipFile(local_zip, "r")
zip_ref.extractall()
zip_ref.close()
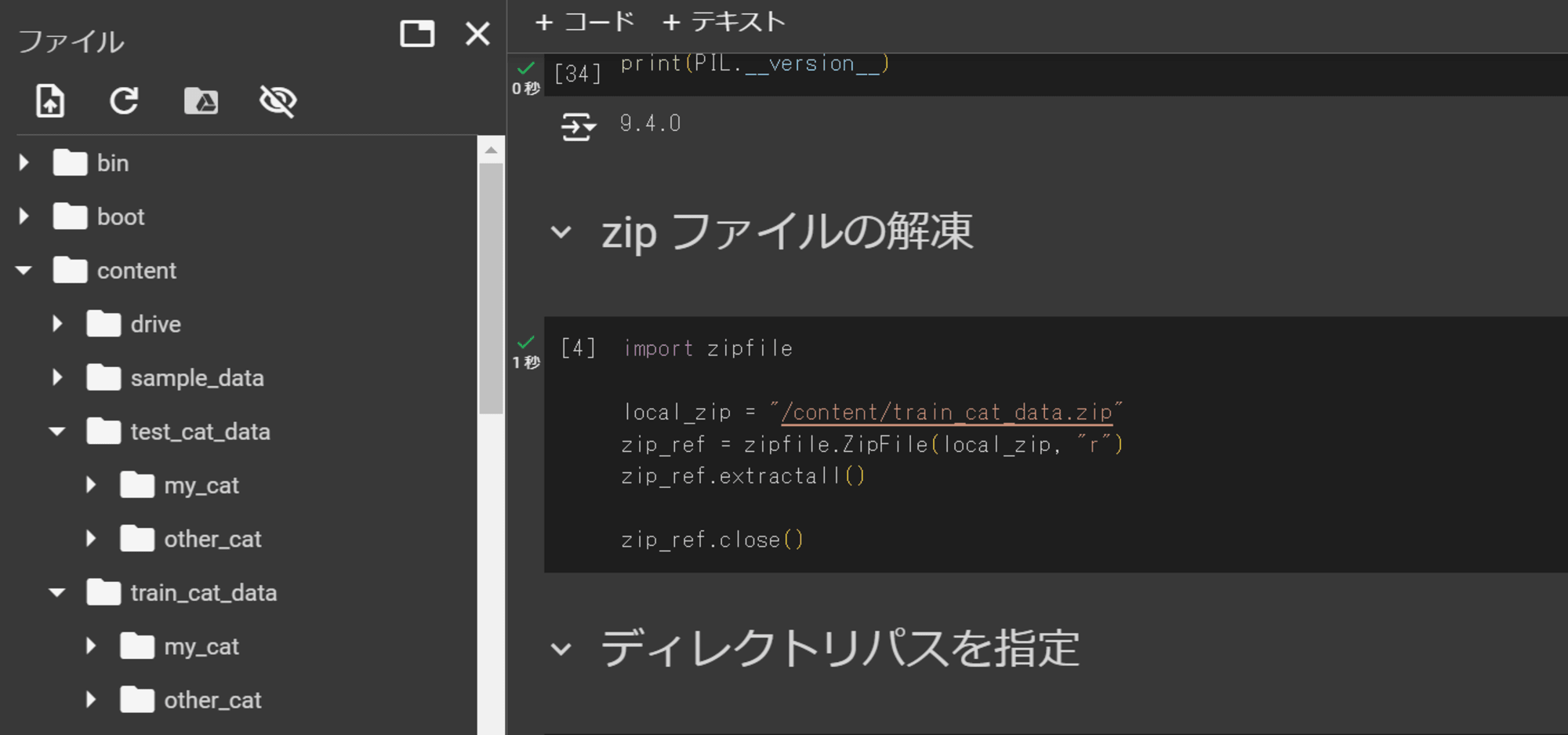
解凍されたファイルが./contents配下に配置されました。
こちらでデータの事前準備が全て完了しました。ここからデータセットを前処理していきます。
データの分割
以下のコードを実行し、解凍したデータに対し学習用データ・検証用データの分割を行います。
データの分割にはimage_dataset_from_directoryモジュールを使用します。
以下のコードを実行します。
# モジュールのインポート
import numpy as np
import os
import tensorflow as tf
import tensorflow_datasets as tfds
# データセットのディレクトリを指定
data_dir = "/content/train_cat_data"
# バッチサイズ、画像の縦横を決める
batch_size = 32
img_height = 180
img_width = 180
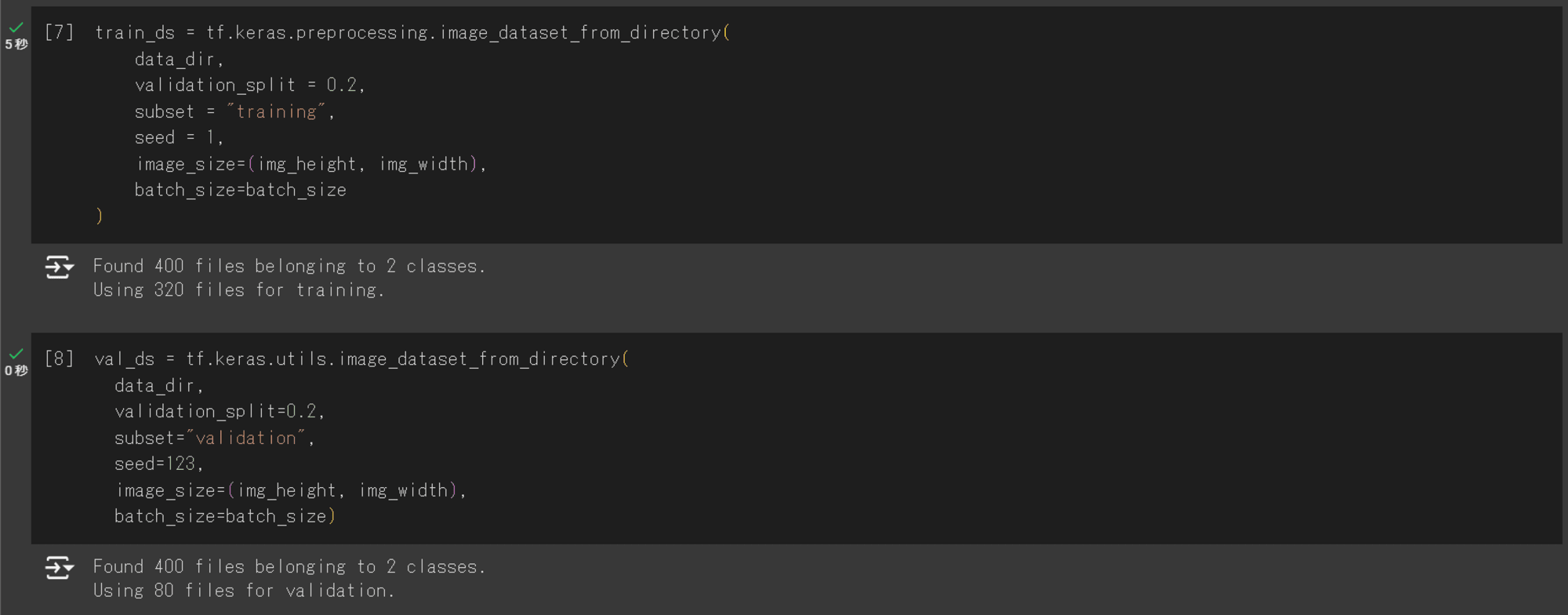
# image_dataset_from_directory モジュールを使用してデータの分割を行う - 学習用データ
train_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split = 0.2,
subset = "training",
seed = 1,
image_size=(img_height, img_width),
batch_size=batch_size
)
# image_dataset_from_directory モジュールを使用してデータの分割を行う - 検証用データ
val_ds = tf.keras.utils.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="validation",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size
)
400データが分割され、学習用データ : 320ファイル、検証用データ : 80ファイルに分割できました。
以下のコードを実行することで、自分の飼い猫 : my_cat と その他の猫 : other_cat の2クラスが存在することも確認できました。
class_names = train_ds.class_names
print(class_names)

データの前処理
画像データの前処理について
用意した画像はサイズなどがバラバラなので、生成するモデルの学習と検証に使用できるよう加工していきます。
データをどのように加工していくかは、以下のサイトと本を参考にしました。
データの前処理方法としては以下の手法があります。
| 大分類 | 処理例 | 詳細 |
|---|---|---|
| 意味のある特徴量を際立たせる | グレースケール変換 → 2値化 | 画像をグレースケール変換(白黒変換)した後、特定の閾値を設けてその値より明るいピクセルを白、それ以外を黒に変換するプロセス。この処理によって画像が完全に白か黒の2値のみで構成される。主にテキスト、シンプルな形状の検出、背景と前景の分離など特定の特徴を際立たせる必要がある場合に用いられる手法 |
| 〃 | 正規化 | 画像内のピクセル値を特定の範囲:0~1、-1~1にスケーリングするプロセス。この処理によって、異なる画像間で照明条件や露出差によるピクセル値の変動を最小限に抑えるのに役立つ。正規化によって、モデルの学習過程がより効率的になり、異なる画像ソースからのデータでも一貫したパフォーマンスを期待できる |
| 意味のない特徴量を除去する(ノイズ除去) | モルフォロジー変換 | 2値化画像をもとに、画像内のピクセルを膨張(線などを太くする処理)させたり、反対に画像内のピクセルを収縮(線などを細くする処理)させたりする処理を指す。膨張と収縮を繰り返すことで、ノイズを除去したり、膨張画像と収縮画像の差分を取ることで物体の輪郭をはっきりさせたいときに用いられる手法 |
| 〃 | 次元圧縮 | データセットの特徴量を減らすプロセス。次元圧縮を行うことにより、計算コストを減らし、機械学習モデルのトレーニング時間を短くすることが可能 |
| 〃 | ヒストグラム | 画像のコントラストを改善したり、特定の画像の特徴量をより際立たせる手法。特徴抽出や分類においてモデルが重要な情報に着目しやすくな |
| 特徴量を増やす(データ拡張) | 画像反転・明度変更 | データセットの母数が少ない場合、データセットを反転させたり、画像の明るさ(明度)変更などを行うことによって、データセットを増やす手法。データセットに合わせた拡張が必要になる |
今回実施する前処理について
今回は、上記の前処理手法の中から正規化、画像のリサイズを行います。
画像のリサイズはデータ分割で完了しているため、正規化を以下のコードで実行します。
画像の中の RGB チャネル値は 0~255 の範囲にあり、ニューラルネットワークに入れるデータには向いていないため、
ここでは、tf.keras.layers.Rescalingを使用して、値を 0~1 の範囲に正規化します。
以下のコードを実行します。
# 正規化レイヤーを定義(ピクセル値を0-255から0-1に変換)
normalization_layer = tf.keras.layers.Rescaling(1./255)
# 訓練データセットに正規化を適用
normalized_ds = train_ds.map(lambda x, y: (normalization_layer(x), y))
# 正規化されたデータセットから1バッチ取得し、バッチの最初の画像を取得
image_batch, labels_batch = next(iter(normalized_ds))
first_image = image_batch[0]
# ピクセル値が 0~1 の値をとるか確認
print(np.min(first_image), np.max(first_image))
出力結果から、ピクセル値が 0~1 を取ることを確認できました。

次に、モデルに投入するデータを確認します。
以下のコードを実行し、データのリサイズが行われていることを確認しました。
import matplotlib.pyplot as plt
plt.figure(figsize=(10, 10))
for images, labels in train_ds.take(1):
for i in range(9):
ax = plt.subplot(3, 3, i + 1)
plt.imshow(images[i].numpy().astype("uint8"))
plt.title(class_names[labels[i]])
plt.axis("off")

データセットの最適化
tf.data.AUTOTUNEを使用することにより、オーバーヘッドの処理を分散させて、余計な待ち時間を削減させる機能があります。
この値を使用することで、TensorFlow は実行時にシステムのパフォーマンスに基づいて最適なパラメータを選択します。
また、以下の通りprefetchを使用することによって、モデルが現在のバッチを処理している間に、データの先読みを行い次のバッチを準備することでモデル学習のパフォーマンスが向上します。
公式ドキュメント:
モデルのトレーニング前に、以下のコードを実行します。
# システムのパフォーマンスに基づいて最適なパラメータを選択
AUTOTUNE = tf.data.AUTOTUNE
# データセットをメモリにキャッシュし、I/O時間を減少させる
# prefetch を使用し、モデルのバッチ処理中に次のデータを読み込む処理を行う
train_ds = train_ds.cache().prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
モデルの構築
今回使用するモデルについて
今回構築するモデルは、CNN(畳み込みニューラルネットワーク)モデルを使用します。
ニューラルネットワークを構築するには、まず1.モデルのレイヤーを定義し、その後2.モデルをコンパイルします。
1.モデルのレイヤーを定義
今回は、TensorFlow のSequentialモデルを使用して CNN を構築します。
ニューラルネットワークは、複数の層(レイヤー)で構成されており、各層は前の層からの入力を受け取り、出力を生成します。Sequentialモデルは、このような層を一直線に繋げて構成されるモデルであり、一つの入力から一つの出力を生成することができます。
各層については以下の通りです。
- 入力層
- 画像データなどの生のデータをネットワークに入力する
- 畳み込み層
- 画像から特徴を抽出する
- 入力データをスキャンし、フィルタと画像の間の畳み込み演算を行い、特徴マップを生成する
- エッジ検出などの低レベルの特徴から、より複雑な特徴まで抽出を行う
- プーリング層
- 特徴マップのサイズを小さくすることで計算量を減らし、過学習を防ぐためのレイヤー
- 全結合層
- ネットワークの最後の部分に位置し、学習した高レベルの特徴を元にクラス分類や回帰などの最終的な出力を生成するレイヤー
- 出力層
- ネットワークの最終層で、全結合層の出力を受け取り、必要な形式の出力(例えば、分類問題ではクラスラベルの確率分布)に変換する
Sequentialモデルは、TensorFlow の Keras という機械学習ライブラリで提供されています。
以下のコードの通り畳み込み層・プーリング層を追加したり、各層ごとのハイパーパラメーターを調整したりすることも可能です。
# 分類するクラスの数を定義(ここでは飼い猫:my_cat とそれ以外の猫:other_cat の2項分類)
num_classes = 2
# Sequentialモデルを使用してCNNを構築
model = tf.keras.Sequential([
# 1層目:畳み込み層とプーリング層
tf.keras.layers.Conv2D(32, 3, activation='relu'),
tf.keras.layers.MaxPooling2D(),
# 2層目:畳み込み層とプーリング層
tf.keras.layers.Conv2D(32, 3, activation='relu'),
tf.keras.layers.MaxPooling2D(),
# 3層目:畳み込み層とプーリング層
tf.keras.layers.Conv2D(32, 3, activation='relu'),
tf.keras.layers.MaxPooling2D(),
# 多次元出力を1次元に変換
tf.keras.layers.Flatten(),
# 全結合層
tf.keras.layers.Dense(128, activation='relu'),
# 出力層
tf.keras.layers.Dense(num_classes, activation='softmax')
])
Keras の Model.summary メソッドを使用して、ニューラルネットワークのすべてのレイヤーを表示します。
model.summary()
次に、モデルのコンパイルを行います。
2.モデルのコンパイル
オプティマイザは、モデルの学習過程を制御し、損失関数を最小化するためのアルゴリズムです。今回はtf.keras.optimizers.Adamオプティマイザを選択します。
損失関数は、モデルの予測と実際の値との差を測定します。今回は多クラス分類問題で使用されるtf.keras.losses.SparseCategoricalCrossentropy損失関数を選択します。
最後に、各トレーニングエポックのトレーニングと検証の精度を表示するにはModel.compileにmetrics引数を渡します。
以下のコードを実行します。
model.compile(
optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
モデルトレーニング
Keras のModel.fitメソッドを使用して、10 エポックのモデルをトレーニングします。
構築した CNN モデルの損失関数(loss),正解率(accuracy)それぞれを可視化したいので、historyにトレーニング履歴を格納します。
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=10
# トレーニング中に実行される追加の処理
callbacks=[
# 早期停止(3エポック改善がなければ停止)
tf.keras.callbacks.EarlyStopping(patience=3),
# 最良モデルの保存
tf.keras.callbacks.ModelCheckpoint('best_model.h5', save_best_only=True)
],
# トレーニング進捗の表示レベル(0=非表示、1=進捗バー、2=1エポックごとに1行)
verbose=1
)
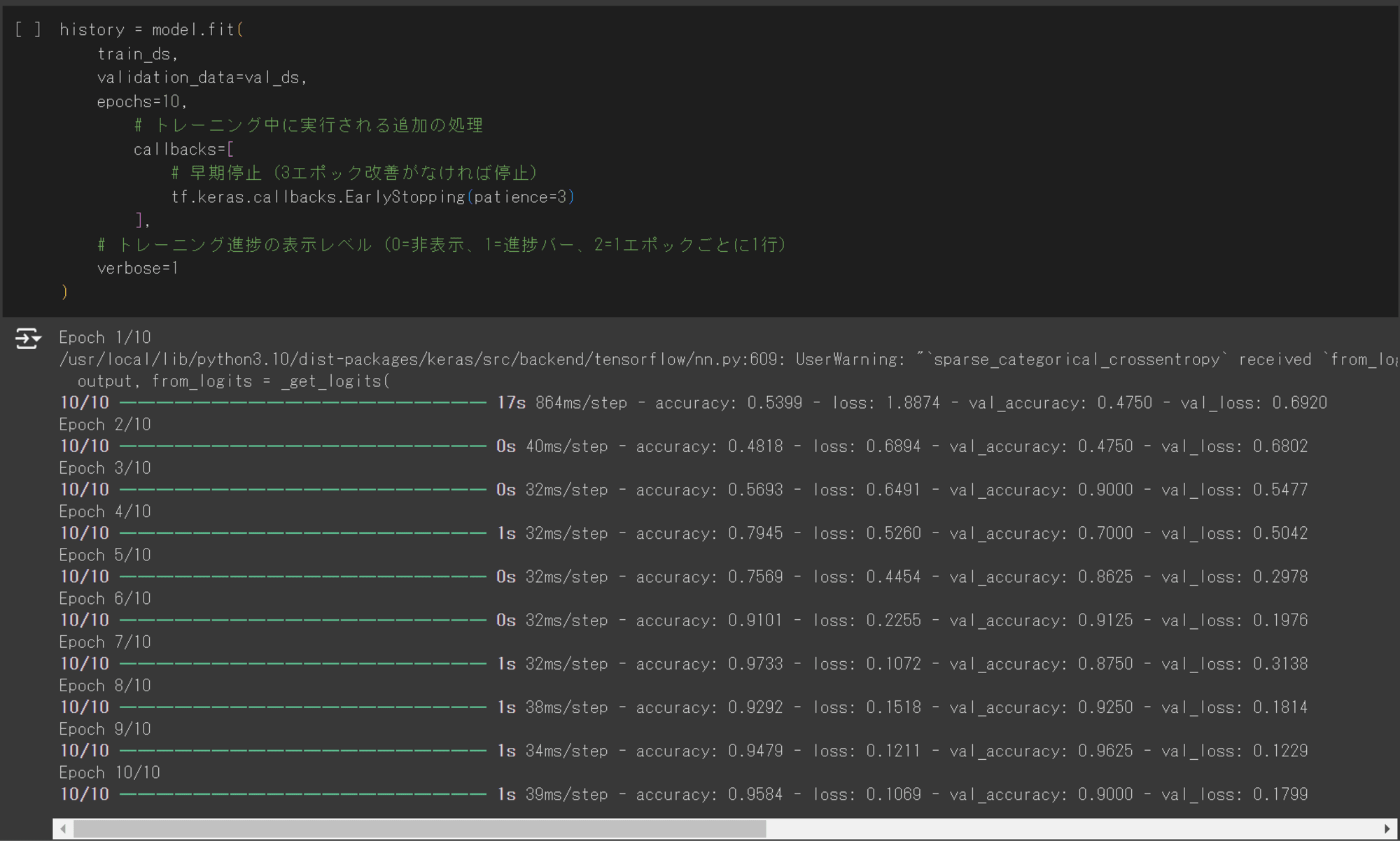
モデルのトレーニングが完了したら、モデルを可視化していきます。
CNN の学習過程を可視化
モデルのトレーニングが完了したので、トレーニングした CNN モデルの学習過程を可視化していきます。
ここでは、「モデルがどのようにトレーニングされているのか」、「モデルの学習中に問題が起こっていないか」を見ていきます。
損失関数(loss)、正解率(accuracy)がモデルのトレーニング中にどのように推移していったのかを可視化します。
以下のコードを実行します。
# グラフのサイズ設定
plt.figure(figsize=(12, 4))
# accuracy の表示
plt.subplot(1, 2, 1)
plt.plot(history.history['accuracy'], label='Training Accuracy')
plt.plot(history.history['val_accuracy'], label='Validation Accuracy')
plt.title('Model Accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend()
# loss の表示
plt.subplot(1, 2, 2)
plt.plot(history.history['loss'], label='Training Loss')
plt.plot(history.history['val_loss'], label='Validation Loss')
plt.title('Model Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
# サブプロット間の間隔を自動調整
plt.tight_layout()
# グラフの表示
plt.show()
上記コードを実行すると、以下の画像が出力されます。
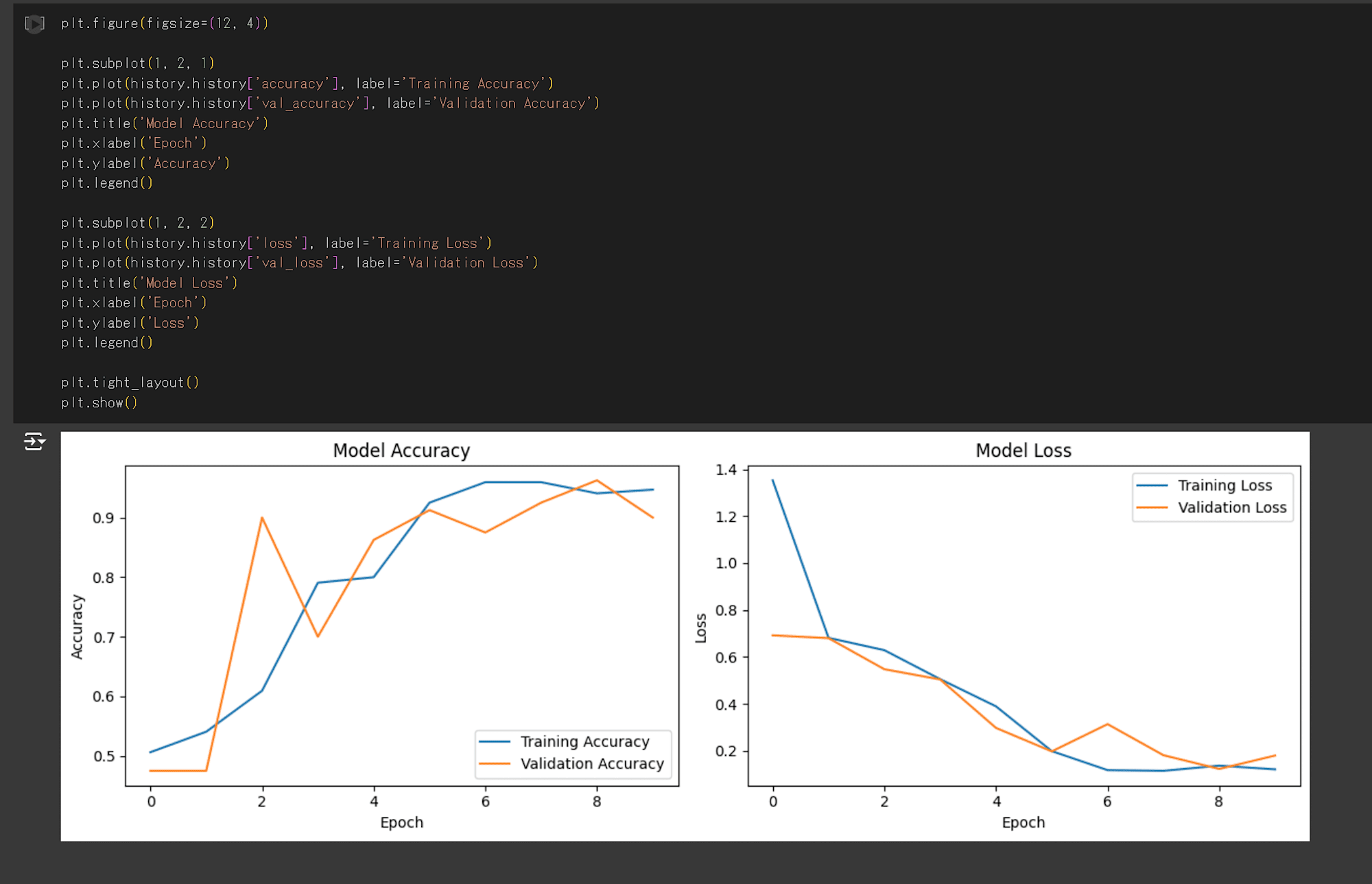
それぞれ、エポック数(モデルにデータを学習させた回数)ごとの損失関数と正解率を出力しています。
グラフを確認すると、6エポック目で正解率はほとんど変化が見られなくなり、検証データの損失関数が増加しています。
そのため、今回の CNN モデルは6エポックで学習を停止するのがよさそうです。
また、損失関数の大幅な増減がないため過学習は発生していないと考えられそうです。
モデルの精度改善については、次回以降のブログでまとめたいと思います。
モデルの精度評価
最後に、テストデータを用いて構築したモデルの精度評価を行います。
データの用意
トレーニングデータと同様に、Google Drive にアップロードしたデータを解凍します。
import zipfile
local_zip = "/content/test_cat_data.zip"
zip_ref = zipfile.ZipFile(local_zip, "r")
zip_ref.extractall()
zip_ref.close()
テストデータのリサイズを行います。
test_ds = tf.keras.utils.image_dataset_from_directory(
"/content/test_cat_data",
image_size=(180, 180),
batch_size=32
)
テストデータでのモデルの予測・評価
分類モデルの性能評価:
以下のコードを実行します。
from sklearn.metrics import classification_report
# テストデータセットで予測を行う
y_pred = model.predict(test_ds)
y_pred_classes = np.argmax(y_pred, axis=1)
y_true = np.concatenate([y for x, y in test_ds], axis=0)
# 分類レポートを表示
print(classification_report(y_true, y_pred_classes, target_names=['my_cat', 'other_cat']))
結果:
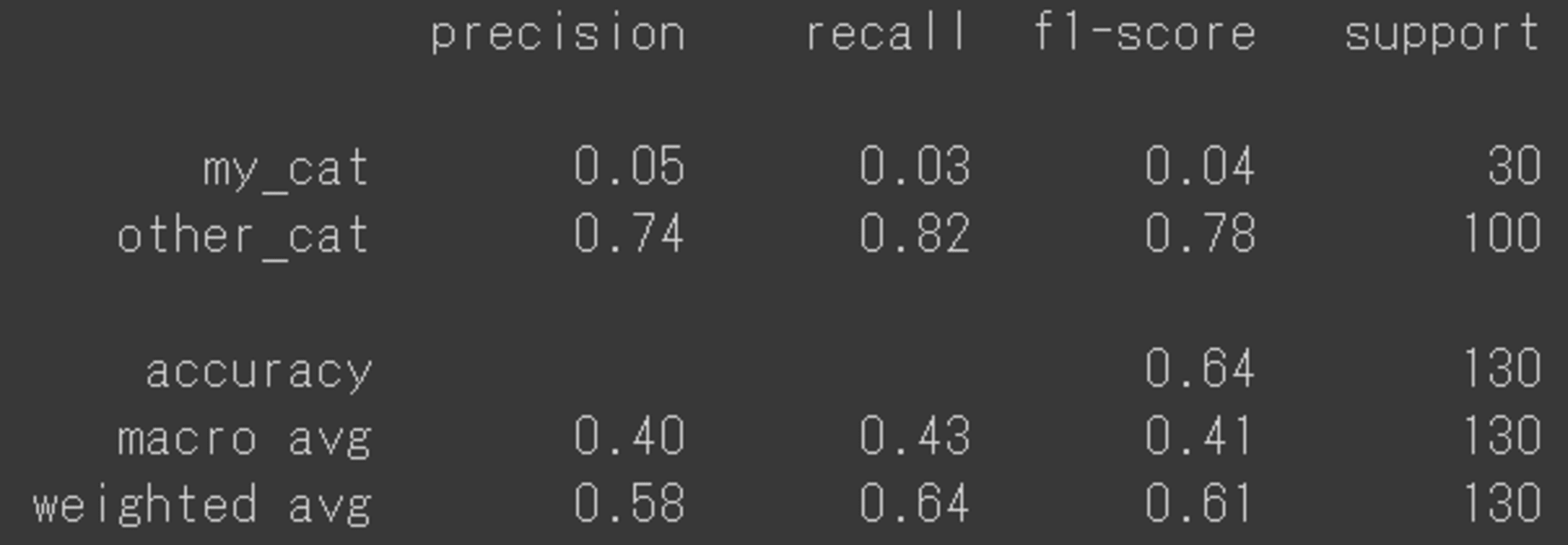
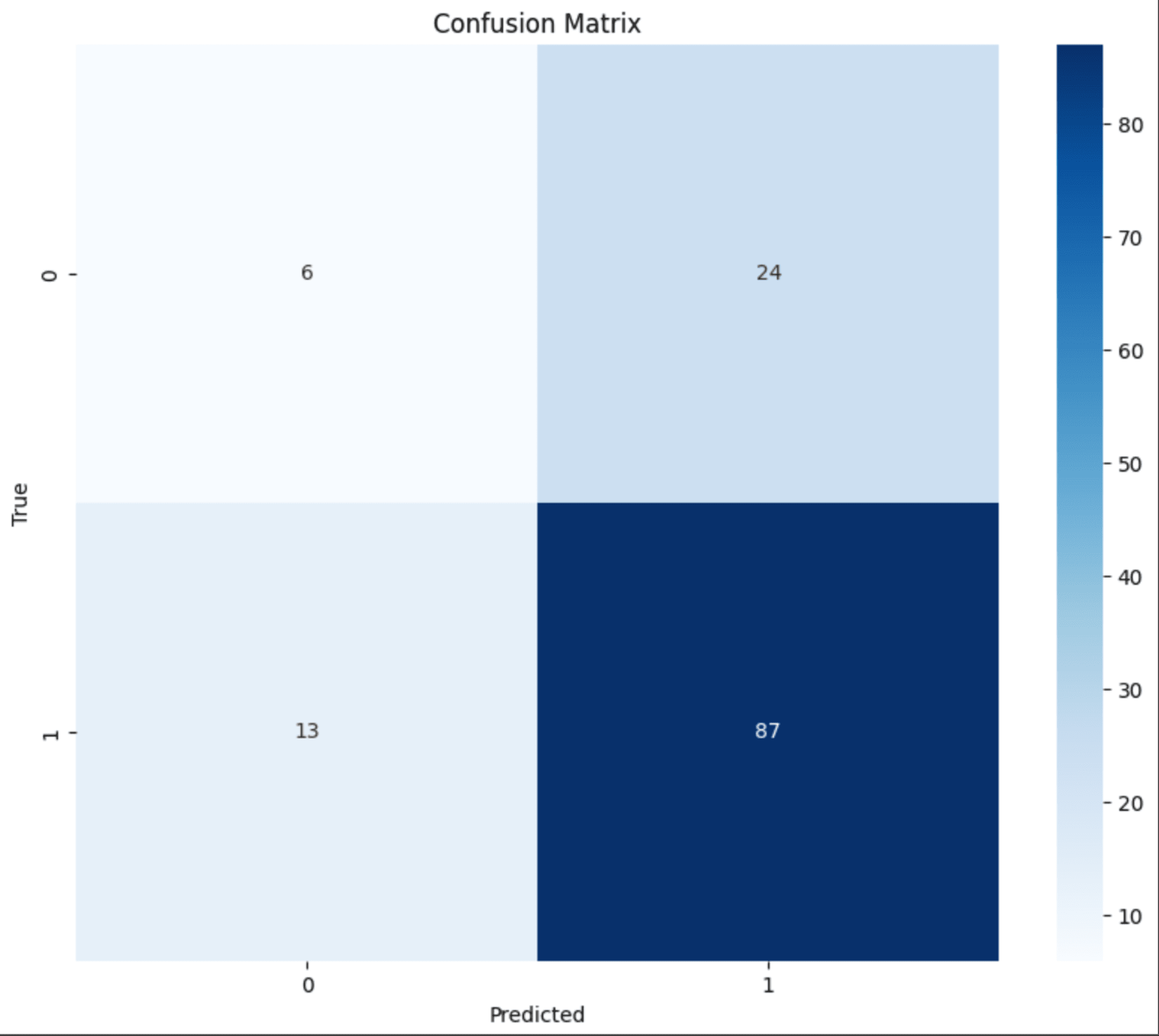
Precision(適合率)、Recall(再現率)を見てみると、my_catとother_catに大幅な乖離があることが分かります。
この結果から、other_catクラスの分類性能は比較的良好ですが、my_catクラスの分類性能が非常に低いことがわかります。
全体的な正解率は64%ですが、クラス間で大きな不均衡があるため、my_catクラスの分類改善が必要そうだということが分かりました。
全体的に画像データが少ないのと、用意した飼い猫の画像は横を向いている画像が多かったため、そのあたりも精度に関係していそうです。
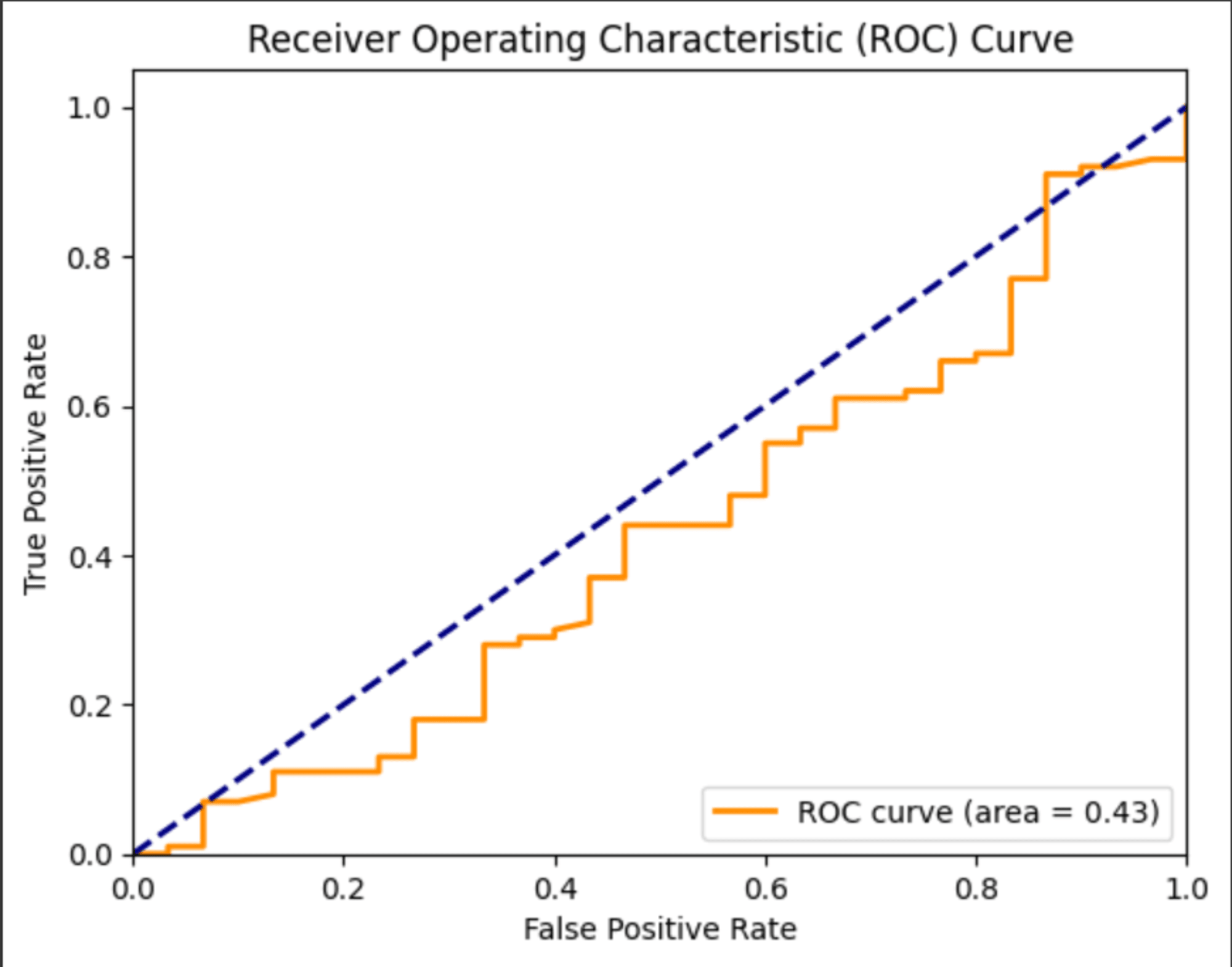
ROC曲線:
from sklearn.metrics import roc_curve, auc
# テストデータセットで予測を行う
y_pred = model.predict(test_ds)
y_true = np.concatenate([y for x, y in test_ds], axis=0)
fpr, tpr, _ = roc_curve(y_true, y_pred[:, 1])
roc_auc = auc(fpr, tpr)
plt.figure()
plt.plot(fpr, tpr, color='darkorange', lw=2, label='ROC curve (area = %0.2f)' % roc_auc)
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic (ROC) Curve')
plt.legend(loc="lower right")
plt.show()
混同行列:
# テストデータセットで予測を行う
y_pred = model.predict(test_ds)
y_pred_classes = np.argmax(y_pred, axis=1)
# 実際のラベルを取得
y_true = np.concatenate([y for x, y in test_ds], axis=0)
# 混同行列を計算
cm = confusion_matrix(y_true, y_pred_classes)
plt.figure(figsize=(10, 8))
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues')
plt.title('Confusion Matrix')
plt.xlabel('Predicted')
plt.ylabel('True')
plt.show()
終わりに
以上で、「TensorFlow で 画像分類モデルを構築してみた」は以上となります。
画像分類の前処理手法や全体の流れが自分の中で整理できたのでよかったです。
次回の記事で、my_catクラスの分類精度向上のために、 エポック数の調整やハイパーパラメータの調整、データ量が少ないためデータの追加やデータ拡張を試してどのぐらいモデルの精度がよくなるかを試していきたいと思います。
ここまで読んでいただきありがとうございました。










